RamboSteve CS 175: Project in AI (in Minecraft)
PROJECT SUMMARY
Project RamboSteve aims to teach an AI agent to efficiently use a sword and bow to kill multiple mob types. Our arena is an enclosed cuboid that spawns one enemy per episode. Currently, the agent is trained on a Q-table to find the optimal strategy for killing an enemy. At the beginning of each episode, the agent and enemy statically spawn facing one another. Following the initial spawn, the agent gets an observation and has multiple actions that it can take, such as moving forward or backward, attacking, using an inventory slot, and switching weapons. Based on the Q-table, the agent must take a chosen action and return a reward to update the Q-table for the given action. Since we use a Q-Table, our state space must be discretized. We keep track of distance, health, and weapons as our states. However it is important to note since the agent’s camera angles are continuous, we simplify our discrete state space by automatically calculating the angle the agent must face prior to taking an action at each observation.
APPROACH
Our approach for our current implementation uses Q-Tabular learning. In short, our implementation is a table of values for every state and action that we define in our environment. We begin by initializing all of our States, Actions, and Rewards (S, A, and R) to be uniform (all zeros). We then make our agent choose an action given an observation. As we observe the rewards that we obtain for each action, we update our table accordingly.
The hyperparameters that we currently train our agent on is alpha = 0.3, gamma = 0.9, epsilon = 0.6, and back_steps = 5.
Our action is chosen based on our Q-Table and epsilon. Given a state, our agent chooses an action in the table with the highest Q-Value with a chance of selecting a random action.
When an action is completed, we must get our new state and reward from the environment, along with updating our Q-Table with the knowledge that is obtained from the previous action.
Originally, we updated our Q-Table using the Bellman Equation. Our implementation is based on the following image.

We then further experimented on our Q-Table by using another equation by adding our old Q-value (oldq) to our learning rate * (G - oldq). Our G value is calculated as follows.
G = sum([gamma ** i * R[i] for i in range(len(R))])
if tau + back_steps < T:
G += gamma ** back_steps * q_table[S[-1]][A[-1]]
Regarding our MDP states, our program separates the world into weapons, distance, health and mob type. For our weapons, our agent can use the switch command to move between either a sword or a bow. However, distance and health are near continuous and cannot be represented in a Q-Table. We solve this problem by discretizing our distance and health states. This reduces our state space significantly and therefore allows our agent to learn more quickly. We also include each of our trained mob types as a state. Our different possible states are displayed as follows.
DISTANCE = ['close', 'near', 'far']
HEALTH = ['low', 'med', 'high']
WEAPONS = ['sword', 'bow']
HEIGHT_CHART = {'Witch':1.95, 'Skeleton':1.95, 'Zombie':1.95}
Every permutation of these states is a cell in our Q-Table. We also have a list of actions that our agent can take. These actions are listed below:
ACTIONS = {'sword': ['move 1', 'move -1', 'strafe 1', 'strafe -1', 'attack 1', 'switch'], 'bow': ['move 1', 'move -1', 'strafe 1', 'strafe -1', 'use 1', 'use 0', 'switch']}
Our current reward function is very basic. We measure our reward on the amount of health lost and damage dealt. Our current reward algorithm is calculated using the health lost and damage dealt per mission, along with our HEALTH_REWARD and DAMAGE_DEALT_REWARD as follows:
health_lost * c.HEALTH_REWARD + damage_dealt * c.DAMAGE_DEALT_REWARD
HEALTH_REWARD is currently set to 10, and DAMAGE_DEALTH_REWARD is set to 15. When an agent loses, our FAILURE_REWARD constant returns a reward of -20. Our current rewards are not too varied and we expect them these numbers to encourage our agent to at least kill the the enemy without losing too much health.
EVALUATION
In order to evaluate our Q-Tabular learning implementation, we trained the agent through 1000 episodes on three different mob types: Witch, Zombie, and Skeleton.
In terms of qualitatative evaluation, we will measure how well our agent fights by observing the amount of damage taken and the amount of damage dealt. This will provide insight about whether the agent is learning to deal damage while avoiding as much damage as possible. Here is a plot on the overall health lost and the overall damage dealt.

On observation, everytime more damage is dealt, less health is lost and vice versa. We believe that this is a good indication that our agent is properly avoiding damage while killing mobs. However, we also notice that the damage dealt and health lost does not converge. This may either be because we have not trained our agent enough, or because our epsilon value causes our decision-making to be too random.
We will now quantitatively measure how well our agent did against the Zombie mob type. Here is a plot showing the ratio of agent deaths to Zombie deaths while fighting zombies.
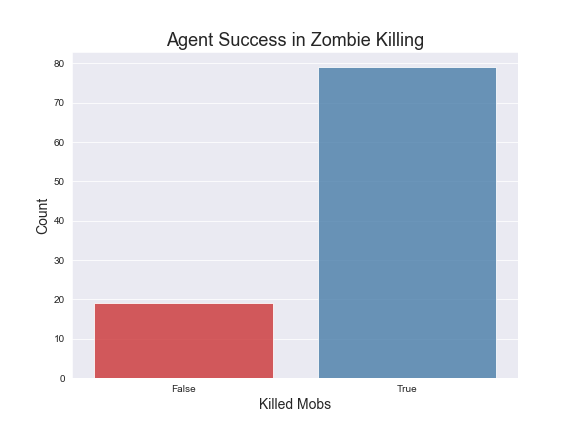
As can be seen, the agent succeeds in killing Zombies most of the time. This indicates that our Q-Tabular learning algorithm is selecting the correct actions to kill a Zombie. However, upon further inspection, we see that the amount of rewards gained from killing zombies neither converges nor improves. This behavior is shown in the graph below.

This behavior may be a result of our reward system. Currently, we only measure rewards by health and damage dealt. By adding more rewards and a more complex state space, our agent may begin to improve marginally.
Upon further thought, we plan on adding a Mission Time reward. This may help our learning algorithm improve by forcing it to find actions that yield the swiftest mission clear time. We will evaluate this feature in the future.
REMAINING GOALS AND CHALLENGES
Goals
Over the remaining course of the project, we plan to continue experimenting with our reward system. For instance, we will implement the mission time as a reward to place emphasis on how fast the agent clears a mission. Additionally, we will change the reward system to have negative rewards to further explore agent behavior. We will also calculate the reward for damage dealt as a function of percent damage to mob type. This is because there are several different mob types with differing amounts of health. By calculating the reward as a percentage we will be able to more accurately represent our agent’s progress. Finally, we plan to add a neural network to better approximate q values that will scale our project to different arena sizes and different mob types.
Challenges
The largest challenge that we currently face is that our agent highly favors usage of the bow over the sword. We will first attempt to explore possible causes of this behavior by changing our hyperparameters. In addition, the mission time reward as discussed in our goal section will likely provide further insight into why the agent may prefer the bow over the sword. This is because the sword deals more damage than the bow and increasing the reward for mission time could possibly lead to the agent choosing the sword over the bow. Some of our smaller challenges involve different mob types and their edge cases. Since our agent will train on different mob types, we must increase the pool of mobs that it can fight. However, some mob types such as the Zombie Pigman, will cause an unknown error in the XML. Also, when a Creeper explodes, the mission fails to terminate correctly because the creeper no longer exists in the entity list. We will need information on the creeper in the entity list to end the mission. We also faced hurdles involving mobs with high health points, such as the witch mob type. Our agent never successfully kills it. We plan to overcome this challenge by exploring different weapon options, such as enchantments to help with killing these mobs. As of now, when an episode completes, the timer continues to play until the end before the episode is terminated. The problem is unknown and we hope to fix the issue to save time and quickly train our agent.
RESOURCES USED
https://github.com/dennybritz/reinforcement-learning
https://github.com/Microsoft/malmo/blob/master/Malmo/samples/Python_examples/tabular_q_learning.py#L375
https://ststevens.github.io/TeamBabylon/
https://medium.com/emergent-future/simple-reinforcement-learning-with-tensorflow-part-0-q-learning-with-tables-and-neural-networks-d195264329d0
http://microsoft.github.io/malmo/0.30.0/Schemas/Mission.html
https://microsoft.github.io/malmo/0.30.0/Documentation/index.html